Pipelining, Dependencies, and Operand Forwarding
CS 441/641 Lecture, Dr. Lawlor
Back in the 1980's, microprocessors took many clock cycles per
instruction, usually at least four clock cycles. They even
printed up tables of clock cycle counts
for various instructions and modes, to help you optimize your
code. This ancient situation still exists with many embedded
processors, like the PIC microcontroller. But this began to
change with the Intel 486, which used "pipelining" to cut the number of clock cycles per instruction (CPI).
The idea behind pipelining is for the CPU to schedule its various components the
same way a sane human would use a washer and dryer. For the sake of
argument, assume you've got:
- Five loads of laundry A B C D E
- They all need to be washed, dried, and folded
- Load E's already clean, and just needs to be dried and folded.
- Each load takes an hour to wash, dry, or fold
So the steps needed are as follows:
Wash A
Dry A
Fold A
Wash B
Dry B
...
Fold D
// don't need to wash E
Dry E
Fold E
Here's how a 286 would execute this program:
Hour
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
Washer
|
A
|
|
|
B
|
|
|
C
|
|
|
D
|
|
|
|
|
Dryer
|
|
A
|
|
|
B
|
|
|
C
|
|
|
D
|
|
E
|
|
Fold
|
|
|
A
|
|
|
B
|
|
|
C
|
|
|
D
|
|
E
|
It's an all-day job, which is clearly stupid, because only one thing is happening at once.
The sensible thing is to make a "pipeline", like an assembly line,
where you start washing load B as soon as you move load A over to the
dryer. So here's how a 486 would do the same work:
Hour
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
Washer
|
A
|
B
|
C
|
D
|
|
|
|
Dryer
|
|
A
|
B
|
C
|
D
|
E
|
|
Fold
|
|
|
A
|
B
|
C
|
D
|
E
|
That is, you start washing load D at the same time as you start folding
load B. This way, everything's busy, which speeds up the overall
program substantially--about a factor of two in this case.
Notice how long it takes to dry C--it really takes an hour, but imagine
you didn't need to do that (e.g., load C is waterproof rain gear). You can't start drying D, since
it's still in the washer. You could start folding C immediately,
but you're busy folding B. So if you leave out "dry C", the
overall process is the *same speed*. This means "dry C" is basically
free--zero clock cycles!
Back in the 1990's, I thought zero-clock instructions were really profound, in a zen kind of way.
Pipeline Stalls and Flushes
In a real CPU, the stages "A", "B", "C", "D", and "E" might be "fetch
instruction from memory", "decode instruction", "read registers needed
for computation", "compute values on registers" (execute phase), and finally "write
result back to register file" (instruction completion or "retirement").
F1 D1 R1 E1 W1 (instruction 1)
F2 D2 R2 E2 W2 (instruction 2)
F3 D3 R3 E3 W3 (instruction 3)
F4 D4 R4 E4 W4 (instruction 4)
F5 D5 R5 E5 W5 (instruction 5)
-> time ->
But consider what happens when you execute a slow instruction like
divide--subsequent instructions might use the divided
value. The CPU hence can't execute these instructions until their
data is ready, and so the CPU must detect these dependencies (also
called "pipeline interlocks") and insert waste "stall cycles" or
("pipeline bubbles") to wait for the needed data. Pipeline stalls
can still cost
performance today--see below for software tricks on minimising
dependencies!
F1 D1 R1 E1 W1 (normal instruction)
F2 D2 R2 E2 E2 E2 E2 E2 E2 W2 (divide: 6 clock cycles)
F3 D3 R3 stall ........ E3 W3 (three stalled-out instructions)
F4 D4 stall ........ R4 E4 W4
F5 stall ........ D5 R5 E5 W5
F6 D6 R6 E6 W6 (continuing normally)
-> time ->
Smarter CPUs will only stall instructions that are waiting on that
data, rather than stopping everything in progress like I've shown above.
Here's a MIPS example that takes an extra clock cycle due to the load
into register 4 immediately being used by the next instruction, the add:
li $3, 5
lw $4, ($25)
add $2, $4, $3
jr $31
nop
(Try this in NetRun now!)
It's even worse with branch instructions--rather than just waiting,
subsequent instructions, even though they're fetched and ready to go,
might never have happened.
So these instructions need to be "flushed" from the pipeline; and
again, it's the CPU's control unit that needs to detect the situation
and do the flushing (anybody starting to smell some complexity here?).
F1 D1 R1 E1 W1 (normal instructions)
F2 D2 R2 E2 Branch!
F3 D3 R3 flush (flushed instructions-that-never-were)
F4 D4 flush
F5 flush
F9 ... (starting over at the branch target)
-> time ->
MIPS branches are pretty good, in that they only take one additional
clock cycle, and you can even specify the instruction to insert during
that clock cycle, called the "branch delay slot" instruction.
li $4, 6
li $3, 5
beq $3,$3,end_of_world
add $2, $3, $4 # Always gets executed (branch delay slot)
# Stuff in here gets jumped over
nop
nop
nop
end_of_world:
jr $31
nop
(Try this in NetRun now!)
Pipelining with Operand Forwarding
Because it might take a few clock cycles to write and then read from
the register file, and it's very common that an instruction needs the
value computed by the immediately preceeding instruction, often real
pipelined CPUs bypass the register file, and pass values directly from the execute stage of one instruction into the execute stage of the next:
F1 D1 R1 E1 W1 (instruction 1)
F2 D2 R2 E2 W2 (instruction 2)
-> time ->
Here E2 needs the result coming out of E1, so you can put in a special
"forwarding" circuit to take it there. Note that if you don't do
forwarding, you would need to insert two
stall cycles to wait for the write and read from the register file:
F1 D1 R1 E1 W1 (instruction 1)
F2 D2 stall R2 E2 W2 (instruction 2)
-> time ->
As usual, the CPU control unit must detect the dependency, decide to
use operand forwarding, and light up the appropriate CPU hardware to
make it happen.
MIPS is a
backronym for "Machine (without) Interlocking Pipeline Stages", because
the designers were really happy with themselves for building in operand
forwarding. It does work, since we can measure that there are no
stalls in this code, despite the back-to-back dependent "add"
instructions:
li $4, 6
add $3, $4, $4
add $2, $3, $4
jr $31
nop
(Try this in NetRun now!)
Architecture-Level Pipelining Differences
Just staring at some diagrams can tell you some of the differences
brought by pipelining. Here's the Intel 8008, a non-pipelined CPU:
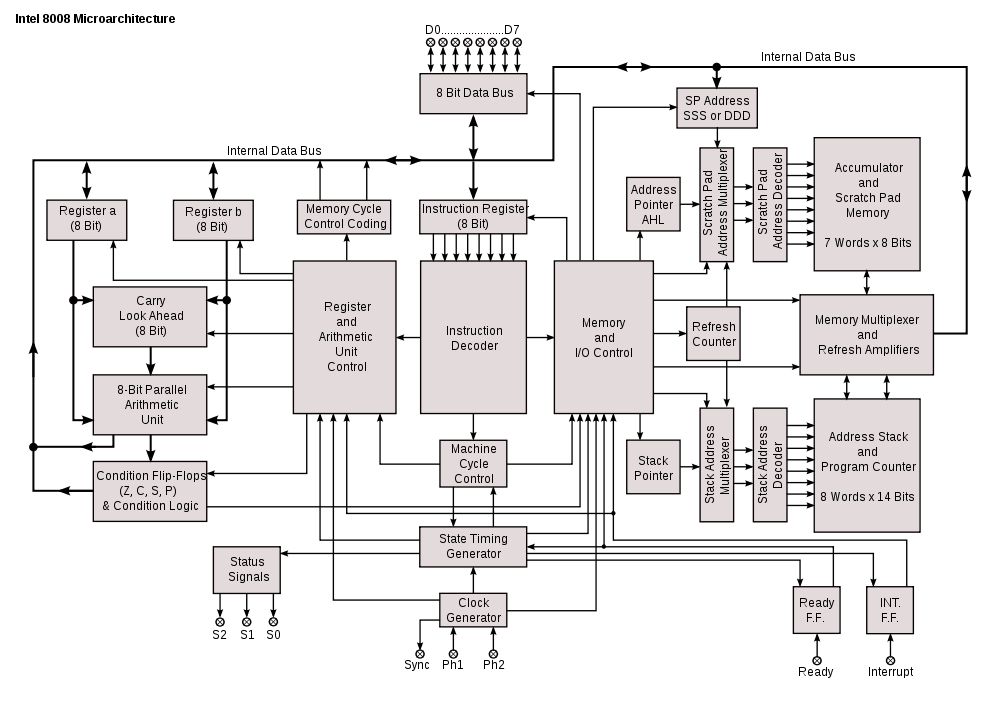
Note that there's just one bus running around the entire CPU, so
there's no possible way that multiple operations could happen at once.
Compare this with the Intel 386, a pipelined CPU:

Note that now there are many separate busses, which allow instruction fetch to happen simultaniously with execution.